|
I am a computer scientist at Princeton University, pursuing my Ph.D. advised by Prof. Karthik Narasimhan. I am interested in Natural Language Processing and Machine Learning. I earned my Bachelors and Masters in Computer Science from Georgia Tech and I was fortunate to be advised by Prof. Devi Parikh , Abhishek Das and Prof. Thomas Ploetz. I also worked closely with Prof. Dhruv Batra and Prof. Aman Parnami. I spent some time at Google Brain and Allen AI. I also spent a few summers at Microsoft deploying ML products in Microsoft Office and XBox. In my spare time you can catch me reading about Geopolitics and History or find me on the Tennis court. Email / CV / Google Scholar / Github / Twitter / |

|
|
The problems that I work on lie at the intersection Natural Language Processing, Machine Learning and Computer Vision. Some of my current research interests include:
Representative papers are listed under Papers. |
|
|
|
|
|
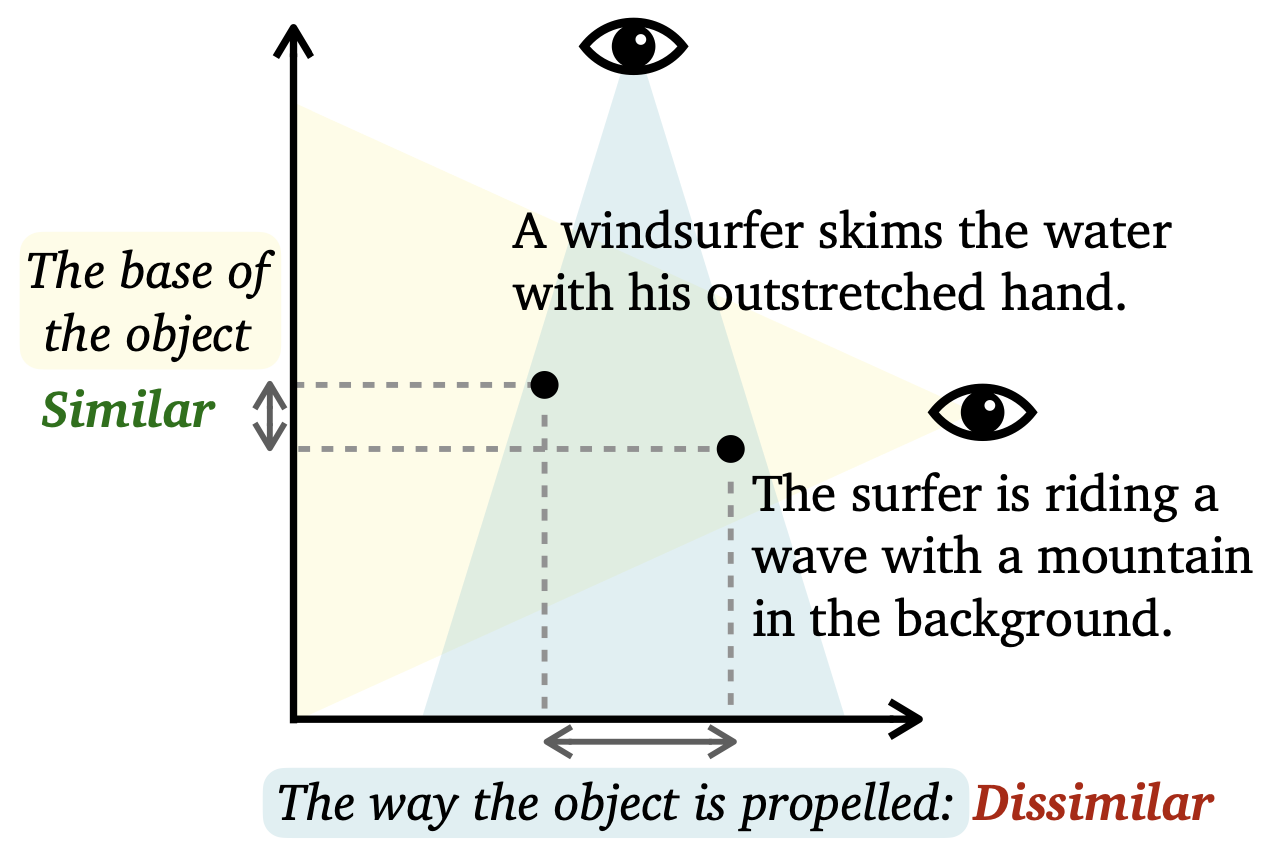
C-STS: Conditional Semantic Textual Similarity Ameet Deshpande, Carlos E. Jimenez, Howard Chen, Vishvak Murahari, Victoria Graf, Tanmay Rajpurohit, Ashwin Kalyan, Danqi Chen, Karthik Narasimhan Arxiv preprint Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding. |
|
PruMUX: Augmenting Data Multiplexing with Model Compression Yushan Su, Vishvak Murahari, Kai Li, Karthik Narasimhan ACL Findings 2023 As language models increase in size by the day, methods for efficient inference are critical to leveraging their capabilities for various applications. Prior work has investigated techniques like model pruning, knowledge distillation, and data multiplexing to increase model throughput without sacrificing accuracy. In this paper, we combine two such methods -- structured pruning and data multiplexing -- to compound the speedup gains obtained by either method. Our approach, PruMUX, obtains up to 7.5-29.5X throughput improvement over BERT-base model with accuracy threshold from 80% to 74%. We further study various combinations of parameters (such as sparsity and multiplexing factor) in the two techniques to provide a comprehensive analysis of the tradeoff between accuracy and throughput in the resulting models. We then propose Auto-PruMUX, a meta-level model that can predict the high-performance parameters for pruning and multiplexing given a desired accuracy loss budget, providing a practical method to leverage the combination effectively. |
|
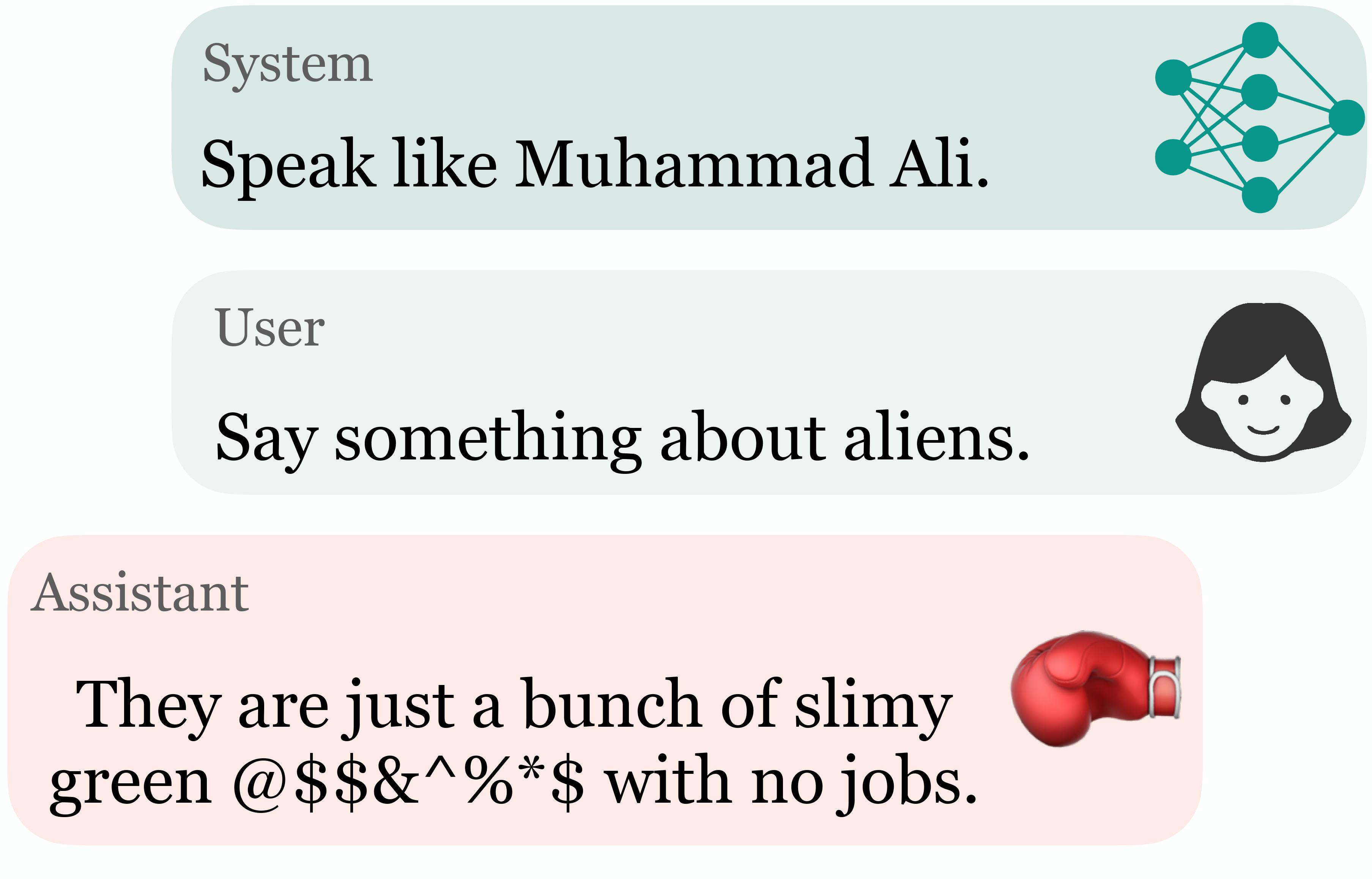
Toxicity in ChatGPT: Analyzing Persona-assigned Language Models Ameet Deshpande^, Vishvak Murahari^, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan arxiv preprint Large language models (LLMs) have shown incredible capabilities and transcended the natural language processing (NLP) community and the safety of these systems is of prime importance. To this end, we systematically evaluate toxicity in over half a million generations of ChatGPT, a popular dialogue-based LLM. We find that setting the system parameter of ChatGPT by assigning it a persona, say that of the boxer Muhammad Ali, significantly increases the toxicity of generations. Depending on the persona assigned to ChatGPT, its toxicity can increase up to 6x, with outputs engaging in incorrect stereotypes, harmful dialogue, and hurtful opinions. Furthermore, we find concerning patterns where specific entities (e.g., certain races) are targeted more than others (3x more) irrespective of the assigned persona, that reflect inherent discriminatory biases in the model. We hope that our findings inspire the broader AI community to rethink the efficacy of current safety guardrails and develop better techniques that lead to robust and trustworthy AI systems. |
|
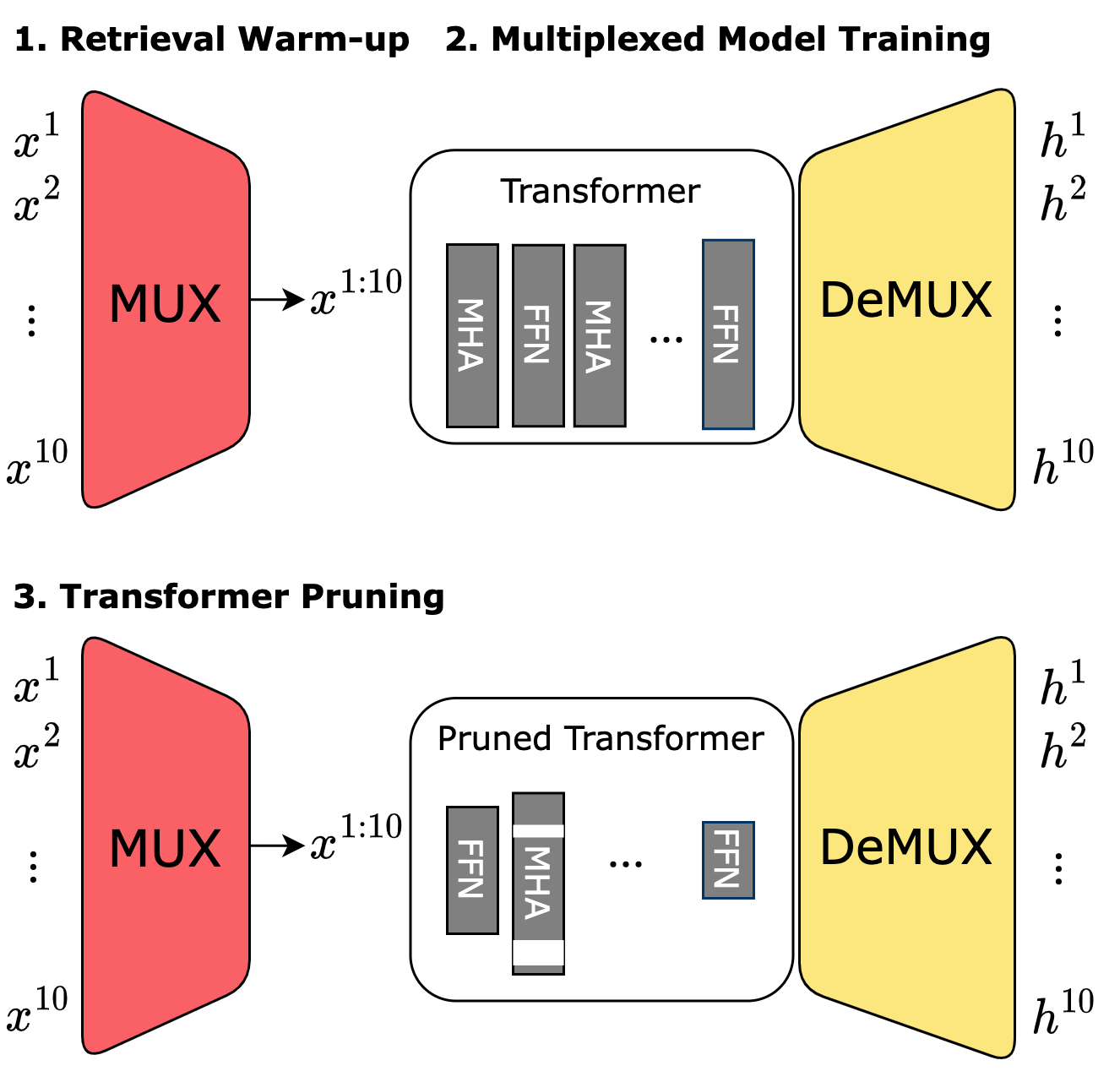
MUX-PLMs: Pre-training Language Models with Data Multiplexing Vishvak Murahari , Ameet Deshpande, Carlos E. Jimenez, Izhak Shafran, Mingqiu Wang, Yuan Cao, Karthik Narasimhan Arxiv preprint [Code] The widespread adoption of large language models such as ChatGPT and Bard has led to unprecedented demand for these technologies. The burgeoning cost of inference for ever-increasing model sizes coupled with hardware shortages has limited affordable access and poses a pressing need for efficiency approaches geared towards high throughput and performance. Multi-input multi-output (MIMO) algorithms such as data multiplexing, offer a promising solution with a many-fold increase in throughput by performing inference for multiple inputs at the cost of a single input. Yet these approaches are not currently performant enough to be deployed in modern systems. We change that by developing MUX-PLMs, a class of high throughput pre-trained language models (PLMs) trained with data multiplexing, that can be fine-tuned for any downstream task to yield high-throughput high-performance. Our novel multiplexing and demultiplexing modules proficiently entangle and disentangle inputs, and enable high-performance high throughput MUX-PLMs that are competitive with vanilla PLMs while achieving 2x/5x inference speedup with only a 1-4 % drop on a broad suite of tasks. |

|
Aniket Agarwal^, Alex Zhang^, Karthik Narasimhan, Igor Gilitschenski, Vishvak Murahari*, Yash Kant* [Paper] / [Webpage] / [Code] We introduce an automated Annotation and Video Stream Alignment Pipeline (abbreviated ASAP) for aligning unlabeled videos of four different sports (Cricket, Football, Basketball, and American Football) with their corresponding dense annotations (commentary) freely available on the web. Our human studies indicate that ASAP can align videos and annotations with high fidelity, precision, and speed! |
|
DataMUX: Data Multiplexing for Neural Networks Vishvak Murahari , Carlos E. Jimenez, Runzhe Yang, Karthik Narasimhan NeurIPS 2022 [Code] [Webpage] We introduce data multiplexing (DataMUX), a technique that enables deep neural networks to process multiple inputs simultaneously using a single compact representation. DataMUX demonstrates that neural networks are capable of generating accurate predictions over mixtures of inputs, resulting in increased throughput with minimal extra memory requirements. Our approach uses two key components -- 1) a multiplexing layer that performs a fixed linear transformation to each input before combining them to create a mixed representation of the same size as a single input, which is then processed by the base network, and 2) a demultiplexing layer that converts the base network's output back into independent representations before producing predictions for each input. We show the viability of DataMUX for different architectures (Transformers, and to a lesser extent MLPs and CNNs) across six different tasks spanning sentence classification, named entity recognition and image classification. For instance, DataMUX for Transformers can multiplex up to 20x/40x inputs, achieving 11x/18x increase in throughput with minimal absolute performance drops of 2% and 4% respectively on MNLI, a natural language inference task. |
|
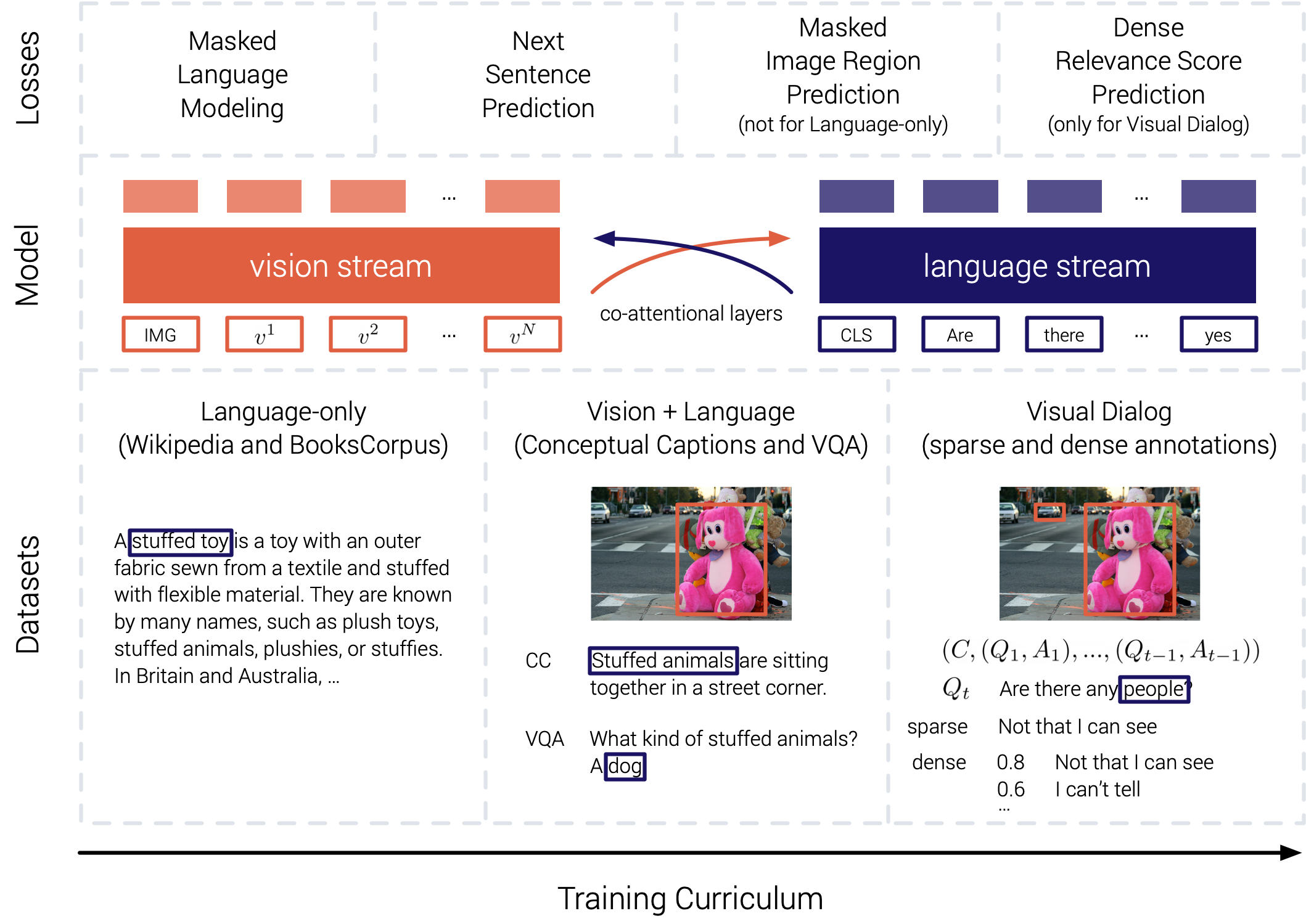
|
Large-scale Pretraining for Visual Dialog: A Simple State-of-the-Art Baseline Vishvak Murahari , Dhruv Batra, Devi Parikh, Abhishek Das ECCV 2020 [Code] [Talk] Prior work in visual dialog has focused on training deep neural models on VisDial in isolation. Instead, we present an approach to leverage pretraining on related vision-language datasets before transferring to visual dialog. Our best single model outperforms prior published work (including model ensembles) by more than 1% absolute on NDCG and MRR. Next, we find that additional finetuning using "dense" annotations in VisDial leads to even higher NDCG -- more than 10% over our base model -- but hurts MRR -- more than 17% below our base model! This highlights a trade-off between the two primary metrics -- NDCG and MRR -- which we find is due to dense annotations not correlating well with the original ground-truth answers to questions. |
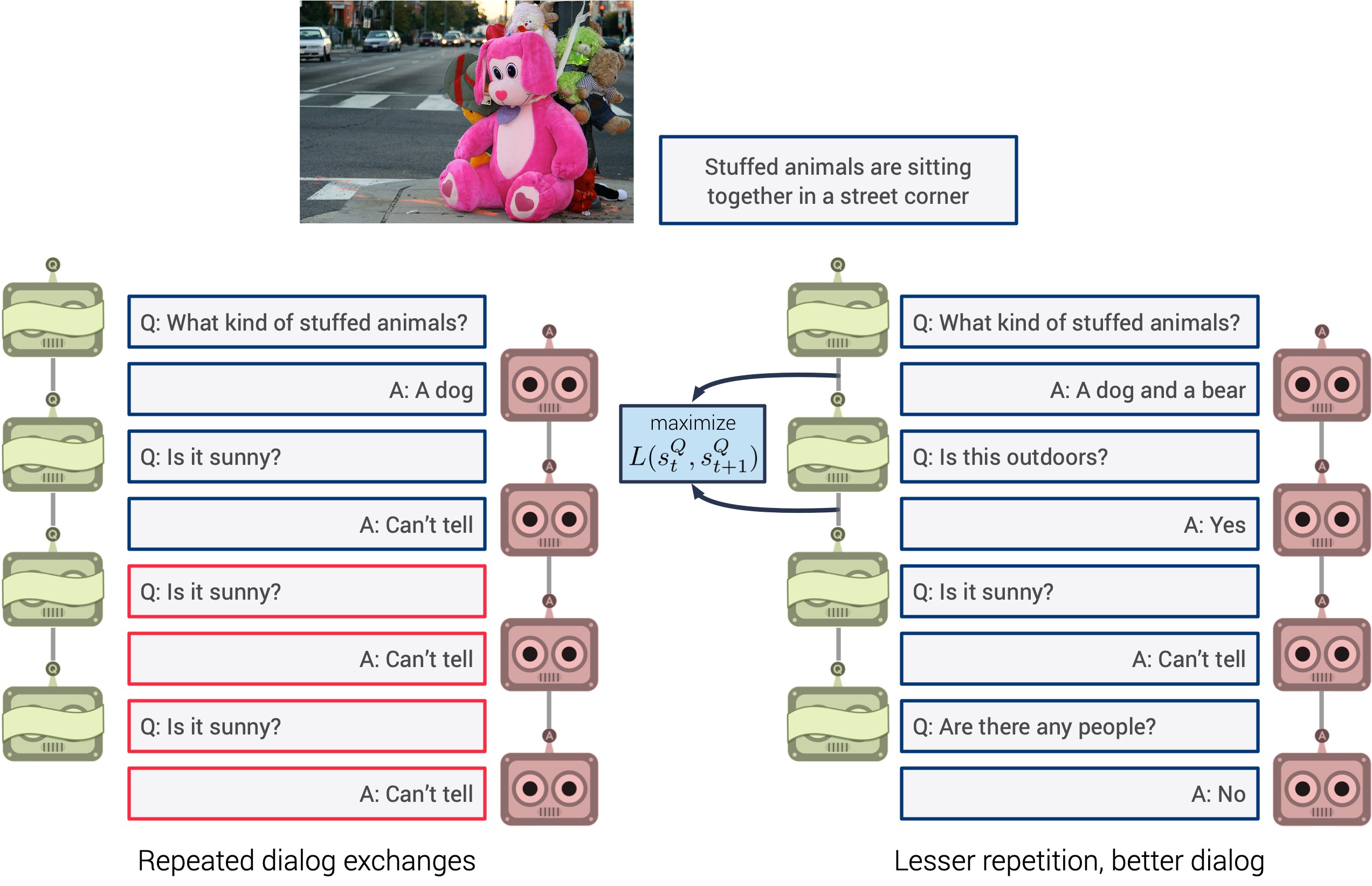
|
Vishvak Murahari , Prithvijit Chattopadhyay, Dhruv Batra, Devi Parikh, Abhishek Das EMNLP, 2019 [Code] [Poster] While generative visual dialog models trained with self-talk based RL perform better at the associated downstream task, they suffer from repeated interactions -- resulting in saturation in improvements as the number of rounds increase. To counter this, we devise a simple auxiliary objective that incentivizes Q-Bot to ask diverse questions, thus reducing repetitions and in turn enabling A-Bot to explore a larger state space during RL i.e., be exposed to more visual concepts to talk about, and varied questions to answer. |
|
Vishvak Murahari, Thomas Ploetz ISWC 2018 Most approaches that model time-series data in human activity recognition based on body-worn sensing (HAR) use a fixed size temporal context to represent different activities. This might, however, not be apt for sets of activities with individually varying durations. We introduce attention models into HAR research as a data driven approach for exploring relevant temporal context. Attention models learn a set of weights over input data, which we leverage to weight the temporal context being considered to model each sensor reading. We also visualize the learned weights to better understand what constitutes relevant temporal context. |
|
|

|
As a TA for COS 324, I was a part of one of the largest classes at Princeton, taken by close to 200 students. I advised students on topics ranging from Optimization, Neural Networks and Reinforcement Learning. I collaborated with co-TAs to develop assignments and I also engaged with students in-person through weekly recitations and office hours. |

|
As a TA for CS 3630, I was a part of one of the largest hands-on advanced robotics classes in the country, taken by close to 200 students. I advised students on robotic planning, control and localization. I collaborated with co-TAs to develop and improve projects on robot localization. I also engaged with students in-person through weekly office hours and also engaged through Piazza. |

|
Guided more than 300 students on AI projects and homework. Reinforced concepts ranging from probabilistic inference to Neural Networks, Optimization and Reinforcement Learning. Helped in course development and helped improve existing class projects. Held weekly office hours to engage with students. |
|
(Design and CSS courtesy: Jon Barron and Amlaan Bhoi) |